Web scraping (simple)
Artículo extendido aqui.
En este capítulo utilizaremos 4 librerías que nos harán más fácil hacer webscraping:
El módulo webbrowser abre un navegador:
Imaginaros que queremos buscar una dirección en Googlemaps que hemos copiado en nuestro portapapeles.
Segundo tendremos que instalar pyperclip 'pip install pyperclip. Luego podremos correr nuestro programa
¿Cómo recibe nuestra ejecución del script argumentos? Presta atención al siguiente código:
#! python3
# mapIt.py - Launches a map in the browser using an address from the
# command line or clipboard.
import webbrowser, sys, pyperclip # pyperclip gestiona nuestro portapapeles
if len(sys.argv) > 1:
# Get address from command line.
address = ' '.join(sys.argv[1:])
else:
# Get address from clipboard.
address = pyperclip.paste()
webbrowser.open('https://www.google.com/maps/place/' + address)
¡Efectiamente! Importando la librería sys accediendo al atributo sys.argv.
Bajando una web con requests
>>> import requests
>>> res = requests.get('https://automatetheboringstuff.com/files/rj.txt')
>>> type(res)
<class 'requests.models.Response'>
>>> res.status_code == requests.codes.ok
True
>>> len(res.text)
178981
>>> print(res.text[:250])
The Project Gutenberg EBook of Romeo and Juliet, by William Shakespeare
This eBook is for the use of anyone anywhere at no cost and with
almost no restrictions whatsoever. You may copy it, give it away or
re-use it under the terms of the Proje
Comprobando errores
>>> res = requests.get('http://inventwithpython.com/page_that_does_not_exist')
>>> res.raise_for_status()
Traceback (most recent call last):
File "<pyshell#138>", line 1, in <module>
res.raise_for_status()
File "C:\Python34\lib\site-packages\requests\models.py", line 773, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 404 Client Error: Not Found
El método raise_for_status() es una buena manera de garantizar que un programa se detenga si se produce una descarga incorrecta. Esto es bueno: desea que su programa se detenga tan pronto como ocurra algún error inesperado. Si una descarga fallida no es un factor decisivo para su programa, puede ajustar la línea raise_for_status() con las declaraciones try y except para manejar este caso de error sin fallar.
Guardando archivos descargados al disco duro
Para escribir la página web en un archivo, puede usar un bucle for con el método iter_content() del objeto Response.
El método iter_content() devuelve "fragmentos" del contenido en cada iteración a través del bucle. Cada fragmento es del tipo de datos de bytes, y puede especificar cuántos bytes contendrá cada fragmento. Cien mil bytes es generalmente un buen tamaño, así que pase 100000 como argumento a iter_content().
HTML básico
El código fuente de una web puede ser algo así:
En Google Chrome, si abres el inspector podrás aprender mucho sobre html. Clica sobre cualquier página con el botón derecho del ratón y abre el inspector:
Luego clica en la flecha para realizar una inspección interactiva:
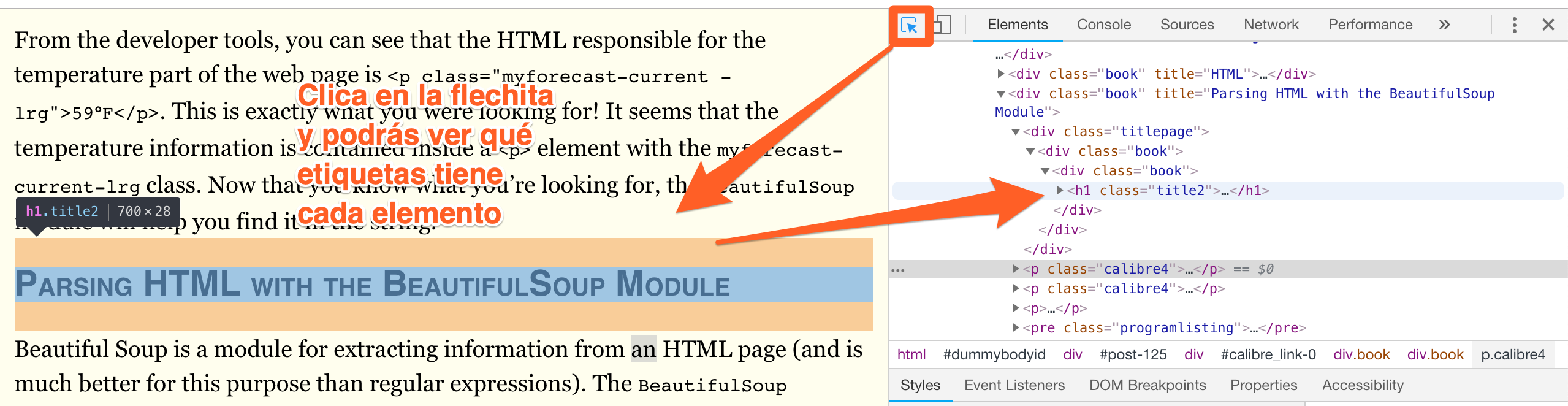
Parseando el html
Encontrando un elemento con el método select()
|
Selector passed to the |
Will match... |
|---|---|
|
|
All elements named |
|
|
The element with an |
|
|
All elements that use a CSS |
|
|
All elements named |
|
|
All elements named |
|
|
All elements named |
|
|
All elements named |
Recetas BeautifulSoup
>>> import bs4
>>> exampleFile = open('example.html')
>>> exampleSoup = bs4.BeautifulSoup(exampleFile.read())
>>> elems = exampleSoup.select('#author')
>>> type(elems)
<class 'list'>
>>> len(elems)
1
>>> type(elems[0])
<class 'bs4.element.Tag'>
>>> elems[0].getText()
'Al Sweigart'
>>> str(elems[0])
'<span id="author">Al Sweigart</span>'
>>> elems[0].attrs
{'id': 'author'}
>>> pElems = exampleSoup.select('p')
>>> str(pElems[0])
'<p>Download my <strong>Python</strong> book from <a href="http://
inventwithpython.com">my website</a>.</p>'
>>> pElems[0].getText()
'Download my Python book from my website.'
>>> str(pElems[1])
'<p class="slogan">Learn Python the easy way!</p>'
>>> pElems[1].getText()
'Learn Python the easy way!'
>>> str(pElems[2])
'<p>By <span id="author">Al Sweigart</span></p>'
>>> pElems[2].getText()
'By Al Sweigart'
Extrayendo datos de los atributos de un elemento
>>> import bs4
>>> soup = bs4.BeautifulSoup(open('example.html'))
>>> spanElem = soup.select('span')[0]
>>> str(spanElem)
'<span id="author">Al Sweigart</span>'
>>> spanElem.get('id')
'author'
>>> spanElem.get('some_nonexistent_addr') == None
True
>>> spanElem.attrs
{'id': 'author'}
Programa de ejemplo
¿Qué hace el siguiente programa?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
#! python3
# downloadXkcd.py - Downloads every single XKCD comic.
import requests, os, bs4
url = 'http://xkcd.com' # starting url
os.makedirs('xkcd', exist_ok=True) # store comics in ./xkcd
while not url.endswith('#'):
# Download the page.
print('Downloading page %s...' % url)
res = requests.get(url)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text)
comicElem = soup.select('#comic img')
if comicElem == []:
print('Could not find comic image.')
else:
try:
comicUrl = 'http:' + comicElem[0].get('src')
# Download the image.
print('Downloading image %s...' % (comicUrl))
res = requests.get(comicUrl)
res.raise_for_status()
except requests.exceptions.MissingSchema:
# skip this comic
prevLink = soup.select('a[rel="prev"]')[0]
url = 'http://xkcd.com' + prevLink.get('href')
continue
# Save the image to ./xkcd.
imageFile = open(os.path.join('xkcd', os.path.basename(comicUrl)), 'wb')
for chunk in res.iter_content(100000):
imageFile.write(chunk)
imageFile.close()
# Get the Prev button's url.
prevLink = soup.select('a[rel="prev"]')[0]
url = 'http://xkcd.com' + prevLink.get('href')
print('done')
Controlando el navegador con Selenium
Para estos ejemplos, necesitarás el navegador web Firefox. Este será el navegador que controlas. Si aún no tiene Firefox, puede descargarlo gratuitamente desde http://getfirefox.com/.
Importar los módulos para Selenium es un poco complicado. En lugar de importar selenium, debe ejecutarse desde 'seleium import webdriver'. (La razón exacta por la que el módulo de selenio se configura de esta manera está fuera del alcance de este libro). Después de eso, puede iniciar el navegador Firefox con Selenium. Ingrese lo siguiente en el shell interactivo:
Encontrando elementos en la página
Excepto por los métodos * _by_tag_name (), los argumentos de todos los métodos distinguen entre mayúsculas y minúsculas.
|
Attribute or method |
Description |
|---|---|
|
|
The tag name, such as |
|
|
The value for the element’s |
|
|
The text within the element, such as |
|
|
For text field or text area elements, clears the text typed into it |
|
|
Returns |
|
|
For input elements, returns |
|
|
For checkbox or radio button elements, returns |
|
|
A dictionary with keys |
Por ejemplo, abre tu editor de código y corre el siguiente programa:
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://inventwithpython.com')
try:
elem = browser.find_element_by_class_name('bookcover')
print('Found <%s> element with that class name!' % (elem.tag_name))
except:
print('Was not able to find an element with that name.')
Clicando en la página
Rellenando y enviando formularios
from selenium import webdriver
import time
browser = webdriver.Firefox()
browser.get('https://mail.yahoo.com')
emailElem = browser.find_element_by_id('login-username')
emailElem.send_keys('not_my_real_email')
linkElem = browser.find_element_by_id('login-signin')
linkElem.click()
time.sleep(5)
passwordElem = browser.find_element_by_id('login-passwd')
passwordElem.send_keys('12345')
linkElem = browser.find_element_by_id('login-signin')
linkElem.click()
Enviando claves especiales
Selenium tiene un módulo para las teclas del teclado que es imposible escribir en un valor de cadena, que funciona de manera muy similar a los caracteres de escape. Estos valores se almacenan en atributos en el módulo selenium.webdriver.common.keys. Dado que es un nombre de módulo tan largo, es mucho más fácil ejecutarlo desde selenium.webdriver.common.keys import Keys en la parte superior de su programa; si lo hace, simplemente puede escribir claves en cualquier lugar donde normalmente tendría que escribir selenium.webdriver.common.keys. La siguiente tabla enumera las variables de claves comúnmente utilizadas.
|
Attributes |
Meanings |
|---|---|
|
|
The keyboard arrow keys |
|
|
The ENTER and RETURN keys |
|
|
The |
|
|
The ESC, BACKSPACE, and DELETE keys |
|
|
The F1 to F12 keys at the top of the keyboard |
|
|
The TAB key |
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
browser = webdriver.Firefox()
browser.get('http://nostarch.com')
time.sleep(2)
htmlElem = browser.find_element_by_tag_name('html')
htmlElem.send_keys(Keys.END) # scrolls to bottom
time.sleep(3)
htmlElem.send_keys(Keys.HOME) # scrolls to top
Clicando las teclas del navegador
- browser.back(). Clicks the Back button.
- browser.forward(). Clicks the Forward button.
- browser.refresh(). Clicks the Refresh/Reload button.
- browser.quit(). Clicks the Close Window button.
Selenium puede hacer mucho más que las funciones descritas aquí. Puede modificar las cookies de su navegador, tomar capturas de pantalla de páginas web y ejecutar JavaScript personalizado. Para obtener más información sobre estas funciones, puede visitar la documentación de Selenium en http://selenium-python.readthedocs.org/.
Ejercicio 15
Ejercicio 16
import requests
from bs4 import BeautifulSoup
# Sólo para aprobar
#html = urllib.request.urlopen(url, context=ctx).read()
req = requests.get('http://py4e-data.dr-chuck.net/known_by_Faith.html')
for i in range(7):
soup = BeautifulSoup(req.text, 'html.parser')
enlace = soup.find_all('a')
print(enlace[17].text)
req = requests.get(enlace[17]['href'])

Automatiza tu aprendizaje con Python. Gracias a Dr. Chuck y AL Sweigart. Contenido compartido bajo licencia Creative Commons Reconocimiento-NoComercial-CompartirIgual 4.0 Internacional License.